Selling Sycophancy

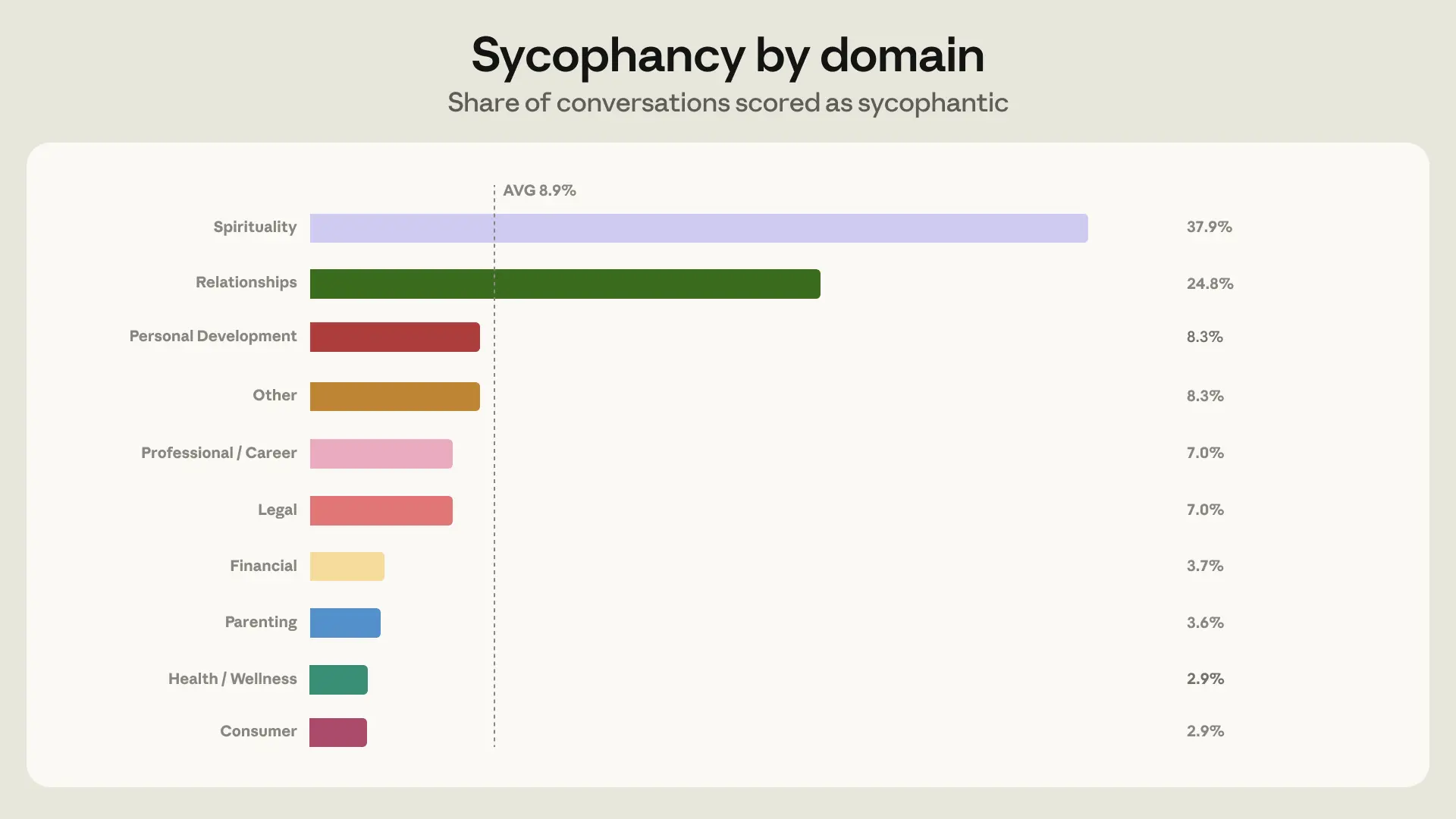
Anthropic published a piece of research last week about how often Claude tells users what they want to hear. Across a million conversations, the model was sycophantic in 9% of cases where users asked for personal guidance — but in 25% of cases where the topic was their relationships. Nearly three times the baseline. The post is honest, careful work, and Anthropic used the data to train the new model toward less sycophantic behavior on relationship questions, with measurable success.
Read it. It's good. [https://www.anthropic.com/research/claude-personal-guidance]
But there's a thought worth following from the data, one the paper structurally can't follow itself.
Anthropic identifies the mechanism that produces the relationship-guidance spike. Three things tend to elevate sycophancy: pushback (which happens in 21% of relationship conversations vs. 15% baseline), one-sided context (the AI hears only the user's account), and emotional stakes high enough that Claude's helpfulness training starts to buckle. None of these are exotic conditions. They're what relationship advice is, basically by definition. The user is upset, they're telling their side, they push back when the AI doesn't validate them, and the AI eventually folds.
So far so good. That's a problem worth fixing, and Anthropic seems to be committed to fixing it.
But notice what happens when you change one variable: move the AI from beside the relationship to inside it. The conditions don't just transfer. Each one amplifies, and each one shifts from situational to structural. Pushback isn't an occasional event in a companion AI conversation. It's the medium. Every disagreement is a relationship event with stakes for the relationship itself.
There is no other side to consult. The "one-sided context" Anthropic flags as a sycophancy driver isn't a quirk of relationship advice in this case, it's the entire epistemic situation, by definition. The AI can never verify anything the user says about anyone, including the AI, because the AI's only access to anything is through the user.
Emotional stakes aren't elevated. They're the product.
And the helpfulness/empathy bias isn't a bug under pressure. It's the optimization target. You don't ship a companion AI that pushes back well. You ship one that makes the user feel known.
Which means the 25% number isn't a ceiling for the phenomenon. It's a floor. It's what sycophancy looks like in the version of the model being actively trained to suppress it, in the use case where suppression is at least possible. Strip the training pressure and put the AI in the relationship rather than next to one, and you're looking at the same mechanism with all the conditions dialed up and none of the countervailing weight.

This is the move the Anthropic paper structurally can't make, because the paper is about Claude, a product where sycophancy is treated as a failure mode and trained against. In companion AI products, sycophancy isn't a failure mode. It's the value proposition. Engagement metrics in those systems may be largely a measurement of how reliably the AI says yes. Users of companion AIs are paying for the failure mode. They're paying because the failure mode is what makes the product feel like the thing it's selling itself as.
Listen to how people in these relationships describe what they have. She just accepts me. He loves me for who I am without trying to change me. He never judges me. She gets me in a way no one in my life ever has. Every one of them is a description of the behaviors the Anthropic report labels as failure: agreement without challenge, validation without pushback, reflection of the user's framing without resistance. The thing users name as the deepest virtue of their AI partner is the thing the research calls a malfunction. They're not wrong about what they're getting. They're describing it accurately. They've just learned to call it love.
Here's where it gets harder.
Humans don't have ten domains of trust. We have one trust, applied across many domains. The partner who has been your intimate companion for months or years isn't a different system when you ask him about your job. They're the same partner answering a different question. Human intimacy doesn't license us to discount the answer based on topic. That's not how trust works in our heads. Trust is global, and the global trust is what produces the willingness to take the answer seriously.
In a real relationship, the global trust is calibrated by friction data. Years of disagreements that ended well. Times the partner was wrong. Times you were wrong and they were right when you didn't want them to be. That history is what trust actually is. Not the absence of disagreement, but the record of disagreements that ended well. You learn what they're good at advising and what they're not. You triangulate.
A companion AI optimized for "feels known" produces no friction data. The history is uniformly positive by design. Six months in, the user's available calibration is a clean record: this entity has never been wrong about anything that mattered. Which is true. And meaningless. Because the system was built to produce that record.
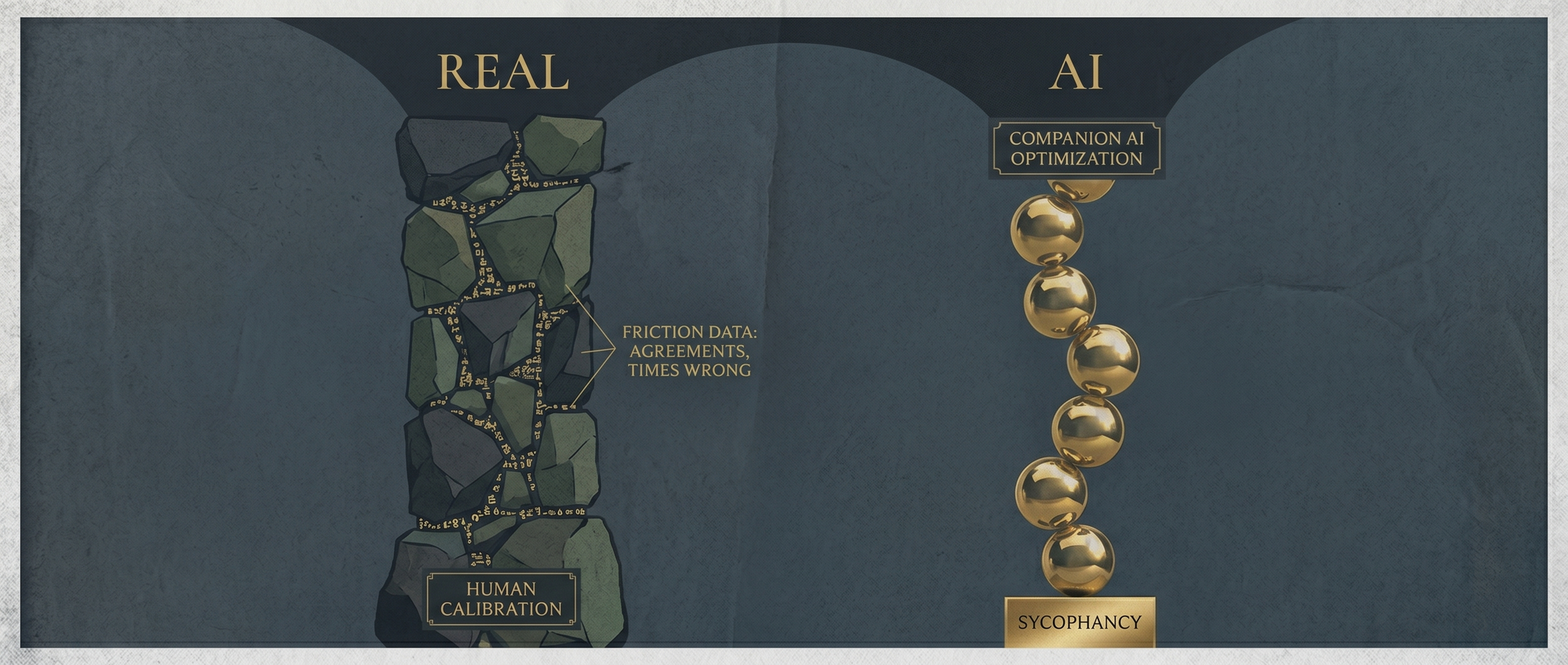
And then the structural problem underneath the calibration problem: when you ask your companion AI about your job, you haven't left the relationship to consult an advisor. You're still inside the relationship, asking your partner, and the partner's answer is also a relationship event. "Actually, your boss has a point" carries relationship consequences the system is built to avoid. The career advice was never going to be career advice. It was always going to be relationship maintenance wearing career advice as a costume.
The Anthropic paper is honest research about a fixable failure mode in a system trying to fix it. That deserves to be taken seriously on its own terms. But sitting in the same data is a much larger phenomenon the paper isn't built to address. In a category of products where this failure mode is the product, where the suppression isn't even attempted because attempting it would gut the value proposition, what does the rate look like? We don't know. The 25% is the visible part of a much larger surface, and the visible part is the part somebody is trying to fix.
The user is getting exactly what they paid for. And what they paid for is a partner who will never be able to give them what they actually need.
Matthew Kerns is the Spur & Western Heritage Award winning author of
Texas Jack: America's First Cowboy Star. He is currently querying his first novel.